
下面的代码:
hiveContext.sql("SELECT * FROM TABLE_NAME WHERE PARTITION_KEY = 'PARTITION_VALUE'")
.rdd
.map{case (row:Row)
=>((row.getString(0), row.getString(12)),
(row.getTimestamp(11), row.getTimestamp(11),
row))}
.filter{case((client, hash),(d1,d2,obj)) => (d1 !=null && d2 !=null)}
.reduceByKey{
case(x, y)=>
if(x._1.before(y._1)){
if(x._2.after(y._2))
(x)
else
(x._1, y._2, y._3)
}else{
if(x._2.after(y._2))
(y._1, x._2, x._3)
else
(y)
}
}.count()
其中ReadDailyFileDataObject是一个case Class,它将行字段作为容器保存。容器是必需的,因为有30列,超过了22的元组限制。
更新了代码,删除了案例类,当我使用Row本身而不是案例类时,我看到了同样的问题。
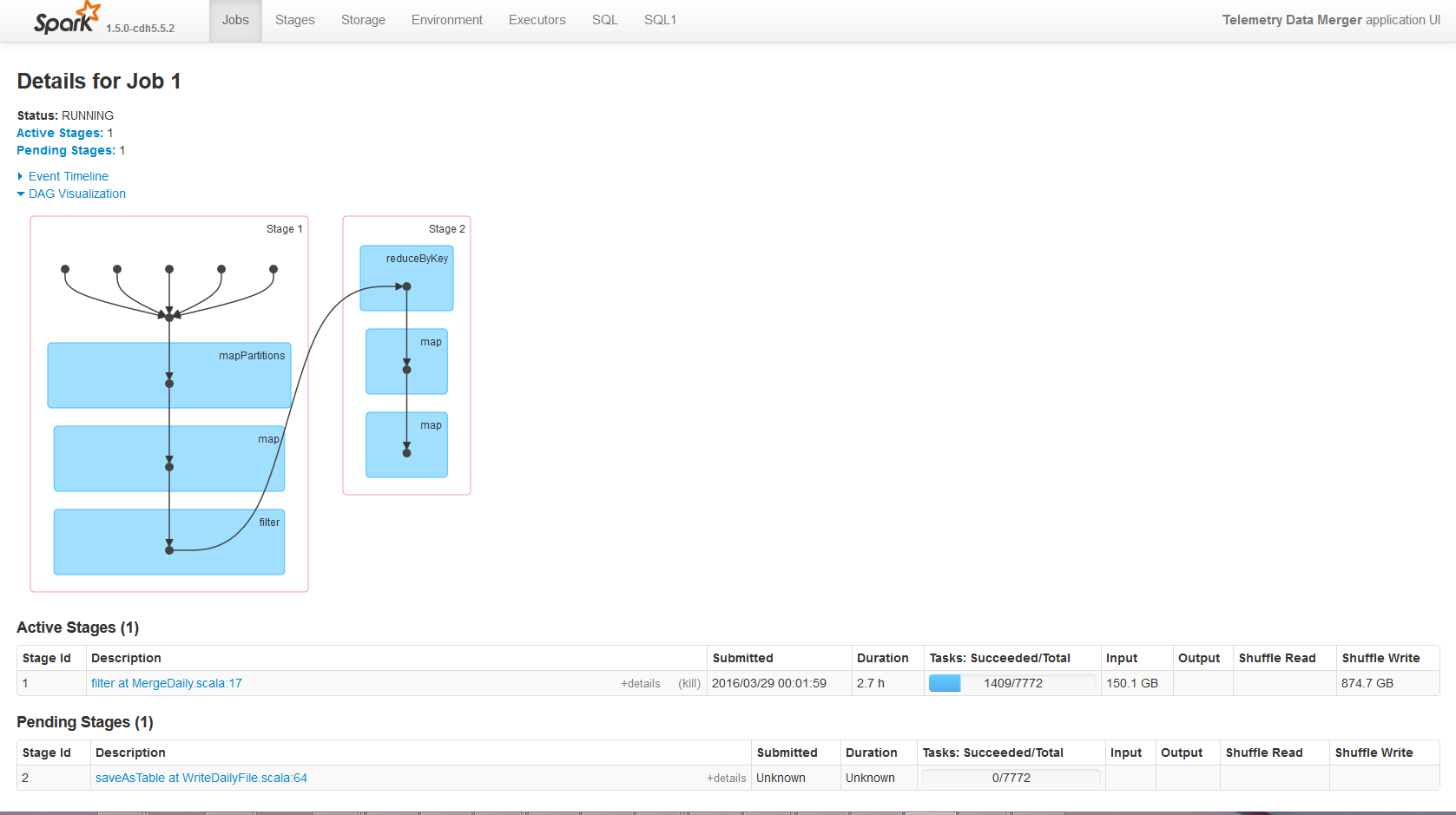
现在目前我看到
任务:10/7772
输入:2.1 GB
随机写入:14.6 GB
如果它有帮助,我试图处理表存储为拼花文件,包含210亿行。
下面是我正在使用的参数,
"spark.yarn.am.memory" -> "10G"
"spark.yarn.am.cores" -> "5"
"spark.driver.cores" -> "5"
"spark.executor.cores" -> "10"
"spark.dynamicAllocation.enabled" -> "true"
"spark.yarn.containerLauncherMaxThreads" -> "120"
"spark.executor.memory" -> "30g"
"spark.driver.memory" -> "10g"
"spark.driver.maxResultSize" -> "9g"
"spark.serializer" -> "org.apache.spark.serializer.KryoSerializer"
"spark.kryoserializer.buffer" -> "10m"
"spark.kryoserializer.buffer.max" -> "2001m"
"spark.akka.frameSize" -> "2020"
SparkContext注册为
new SparkContext("yarn-client", SPARK_SCALA_APP_NAME, sparkConf)
在纱线上,我看到了
分配CPUVCore:95
分配内存:309 GB
运行容器:10
当您将鼠标悬停在InputOutputShuffle ReadShuffle Write上时,显示的提示很好地解释了它们自己:
输入:从Hadoop或Spark存储读取的字节和记录。
输出:写入Hadoop的字节和记录。
SHUFFLE_WRITE:写入磁盘的字节和记录,以便在未来阶段被随机读取。
Shuffle_READ:读取的总混洗字节和记录(包括本地读取的数据和从远程执行器读取的数据)。
在您的情况下,150.1GB占所有1409完成任务的输入大小(即迄今为止从HDFS读取的总大小),874GB占所有1409完成任务在节点本地磁盘上的写入。
你可以参考Map Reduce Programming中简化器中混洗和排序阶段的目的是什么?很好地了解整体混洗功能。
没有代码实际上很难提供答案,但您可能会多次查看数据,因此您正在处理的总容量实际上是原始数据的“X”倍。
你能发布你正在运行的代码吗?
编辑
查看代码,我以前遇到过这种问题,这是由于Row的序列化,所以这可能也是您的情况。
什么是“ReadDailyFileDataObject”?它是一个类,一个案例类吗?
我会首先尝试像这样运行您的代码:
hiveContext.sql("SELECT * FROM TABLE_NAME WHERE PARTITION_KEY = 'PARTITION_VALUE'")
.rdd
.map{case (row:Row)
=>((row.get(0).asInstanceOf[String], row.get(12).asInstanceOf[String]),
(row.get(11).asInstanceOf[Timestamp], row.get(11).asInstanceOf[Timestamp]))}
.filter{case((client, hash),(d1,d2)) => (d1 !=null && d2 !=null)}
.reduceByKey{
case(x, y)=>
if(x._1.before(y._1)){
if(x._2.after(y._2))
(x)
else
(x._1, y._2)
}else{
if(x._2.after(y._2))
(y._1, x._2)
else
(y)
}
}.count()
如果这解决了您的混洗问题,那么您可以稍微重构一下:-如果还没有,请将其作为案例类。-像“ReadDailyFileDataObject(row. getInt(0),row.getString(1)等”一样创建它
希望这算是一个答案,并帮助你找到瓶颈。
